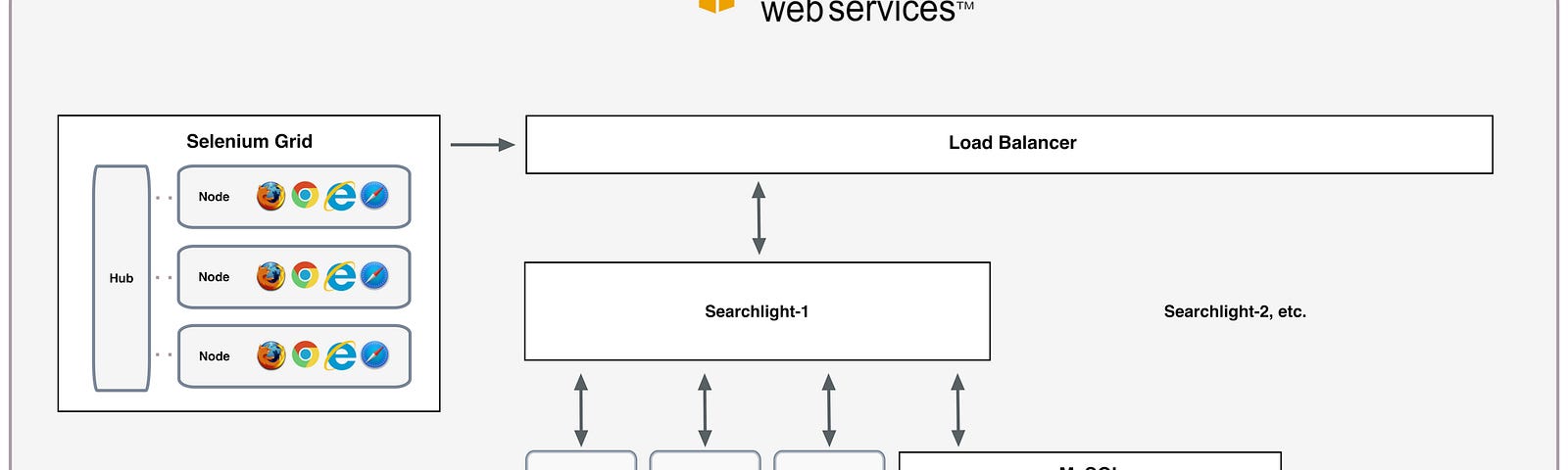
The issue with Spring Cloud AWS Messaging and its @SqsListener annotation is that it cannot process more than 10 concurrent messages.
At Conductor, we deal with pretty big data sets and provide users with a rich set of data…
Technical debt is pretty much any code anyone wrote last week. It’s all around us, binds us, and basically duct-tapes-and-glues the tech world together. Tech Debt is a part of life and, while we all want to ensure all our…
At Conductor, our systems generate over 10 million lines of logs every day. On a particularly…
Today, we’re open sourcing an in-house Java 8 stream utility library, which can aggregate, merge, or join streams in a memory efficient way. To skip right to the code, check out the github repo.
Cassandra’s distributed architecture enables a high write throughput compared to other NoSQL and SQL database systems. Most benchmarks focus on incremental writes, but data can also be efficiently ingested by Cassandra in bulk. Bulk loading is an attractive option when…