
Using Python to Power Up Insights For Content Briefs, SEO Recommendations & Strategy
Find out how you can use this Python script to analyze top performing content to find actionable SEO, content & customer insights for your campaigns.
Over the past 12 months or so I’ve shared some content around how, as part of an ongoing struggle effort to learn Python, I have been using this incredibly accessible programming language to analyse language trends in the SERP .
The reason for this has been that we know Google algorithmically rewrites large portions of the content displayed in the SERPs (84% according to our study ). It’s likely that this rewriting process happens because Google wants to highlight content from a page that it thinks is more likely to encourage a click from a searcher.
According to our study, Google algorithmically rewrites ~84% of content displayed on the SERPs.
Therefore, we can attempt to lean on Google’s powerful search algorithm to help us spot patterns that will help us better understand what our audience wants and, dare I say it, their intent.
Using Python to Analyze the Content on Ranking Landing Pages
SERP insights can become a valuable asset when we think about how we might structure our landing pages, the language we use to speak to our audience, how we structure our calls to action, and can even inform decisions we make across non-organic marketing channels.
While these insights can be incredibly useful, I have also been keen to develop the concept. Can we use the same methodology to analyse ranking landing pages in more detail, and can Python help us automate the process?
Well, yes we can! This article will take you through some updated processes to help you analyse the content on ranking landing pages, and I’ll be sharing a Jupyter Notebook /Google Colab so you can run it for yourself.
Note – I have tried to make this as accessible as possible but it does probably require some foundational knowledge. There are links throughout this piece to resources that should help explain some of the terminology used, but please don’t be intimidated if it all just looks like a lot of code!
How can this script help improve SEO performance?
Our output from running the Python script is going to be seven data points we can reference to help us improve on-page optimization, the content briefs we create, and the performance of our overall content strategy. Each of these pieces of analysis will be explored in more detail in this article:
- Ranking Vocabulary – Part of Speech (PoS) analysis of top-ranking landing pages for our keywords
- Ranking Entities – Commonly occurring named entities referenced in content in top ranking landing pages for our keywords
- Topical Resonance – The most ‘resonant’ words/language to the topics we are searching for with our target keywords
- Title Co-Occurrence – N-Gram analysis of the header tags on pages ranking for our target keywords
- Topical Groupings – A collection of potential ‘topical groupings’ based on the language used on our top ranking pages
- SERP Analysis – Further PoS analysis but this time looking at the content of the titles and descriptions that feature in the SERPs
- Question Extraction – Used regex to compile a list of questions in ranking content to help inform how we structure landing pages and what other supporting content we might want to create
Initial caveats
Before diving in, I would be remiss not to throw out a couple of caveats. Firstly, this is not about trying to find some perfect formula for on-page optimisation. Nor is it about trying to ‘reverse engineer’ certain aspects of Google’s search algorithm.
This is about understanding the audience we want to reach; their needs, their wants, and their intent and using that information to develop content assets and strategy that is truly customer-first.
I will also add that the below methods are a jumping off point rather than a finished product; I am still improving my understanding of Python, so there will be lots of opportunities to improve and streamline these methods, and I welcome input as other SEOs experiment with these tactics.
This is about understanding the audience we want to reach; their needs, their wants, and their intent and using that information to develop content assets and strategy that is truly customer-first.
All that said, here’s a link to Google Colabs (please make a copy for yourself):
https://colab.research.google.com/drive/1rKa_qWMn_5pn3HkbS33PA9SACzUnQad-
How does the Python script work?
Step 1 – Gather List of SERP URLs to Analyse
The first part of the script is what extracts the content that we’re going to analyse. It works by letting you enter a number of keywords that you want to analyse:

Naturally in this example, we’ll be looking at some content about wonderful, wonderful dogs.
The script will then compile a list of ‘SERP URLs’ that we want to analyse for those keywords. In this example, we’re asking it to look at the top five results (&num=5) for UK search results (&cr=GB).

Those settings are all easily customisable and can be configured however you like.
Step 2 – Create List of URLs Ranking for Target Keywords
We will then use the Beautiful Soup library to help us extract certain elements from that SERP page, namely the ranking URLs (i.e. the pages that rank for that query), ranking titles, and ranking descriptions for each of those results.
The output you’ll see should look something like this; a list of URLs that has been de-duplicated:

What we have so far is a list of URLs ranking in the top five search results for our inputted list of keywords.
So far, so good. But how do we extract the content we need to analyse from those pages?
Step 3 – Extract Content From Ranking URLs
We can again use Beautiful Soup to help us.
We will use a ‘for loop ‘ to iterate through that list of URLs and capture all of the paragraph tags and all H1-H4 tags in a ‘dictionary ‘. Think of this as a document in our script where the content from ranking URLs is going to be stored. It is this ‘document’ containing our extracted website copy that we will be analysing:

What we’ll end up with (hopefully….) is something that looks like this (this is the ‘dictionary’ referenced above):

It looks a bit messy, but already in just two cells of Python we’ve been able to extract and store the content ranking for our queries.
7 Workflows to Inform Content & Optimization Strategies
That’s a good start, but now let’s think about the analysis we can run to inform our content strategy and optimisation decisions.
Workflow 1 – Part of Speech (PoS) Tagging Analysis
Part of Speech (PoS) tagging is a process to analyse each of the individual words in the content we have extracted from the ranking landing pages, and define whether it is a noun, verb, adjective etc.
The PoS tag is going to be based both on the definition of the work and its context (i.e. where it appears in relation to other words). This process works by building a ‘dataframe’ from our extracted content, mapping a PoS tag to each of the words, then creating a new dataframeFrame
Frames can be laid down in HTML code to create clear structures for a website’s content.
Learn More that shows a clean breakdown of how many times a word appears as each PoS tag.
The output will look something like this:
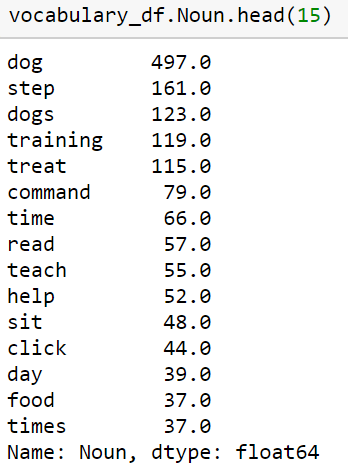
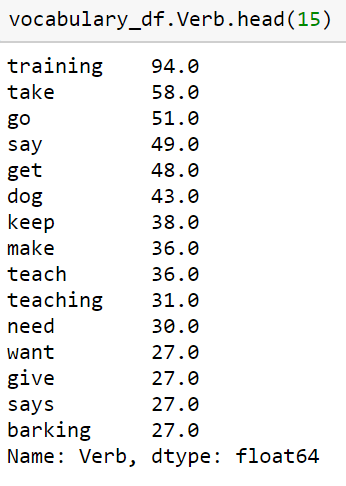
This can be very useful as you look for trends in the type of language or the topics that are appearing constantly appearing in the ranking content for our target keywords.
We can start to think about how some of these language trends might be connected to our target keywords and incorporate that into content briefs to improve page ranking for our keywords.
Workflow 2 – Named Entity Extraction
The relationships between entities and how they are connected to certain topics is becoming a more prominent topic for SEOs in the age of things not strings .
Therefore, it can be particularly useful to be able to identify which named entities are consistently being associated with a subject. That is the the purpose of the next workflow here, which looks through the content we have extracted and looks for all occurrences of named entities.
Unfortunately, my dog training keywords weren’t the best for this example so here’s one for everyone’s second favorite topic…Brexit?

This is our output dataframe, which is currently ordered by the most frequently occurring ‘organisations’ – though this is entirely flexible. It is pulled together thanks largely to the Spacy Python library and a handy function we created that looks through the content we have extracted; finds all the named entities; and labels them accordingly.

Here is a list of all the various ‘entity types’ that Spacy can find in your content. The script will then count how many times each named entity occurs so it can compile the dataframe you see above.
Our output dataframe shows each of the entities it has found in a row, then the columns show a count of how many times that entity has been found based on its label.
If we’re writing or planning content around Brexit, this can give us a clear steer on the entities that Google might see as being associated with that topic, and referencing them in our content could give it an authoritative edge (but please…let’s not go down the route of ‘entity stuffing’).
Workflow 3 – Topical Resonance Analysis
This process uses machine learning (unsupervised ) to help us ascertain how closely certain words are connected to broader topic we’re searching for.
In other words, we’re attempting to score the topical salience of certain words to help us understand how prominent they should be within the copy we’re creating to target the keywordKeyword
A keyword is what users write into a search engine when they want to find something specific.
Learn More.
This works by utilising two libraries, primarily NLTK and NetworkX . It will analyse compound noun phrases (created by only looking at sentences containing a noun and an adjective, then creating a list of those words) and building a network from nouns and adjectives that occur in the same sentence.
It will then use betweenness_centrality to attempt to identify the most central words within that network (i.e. the most important words).
The output is a dataframe that contains a word and its resonance to the topics we are searching for:
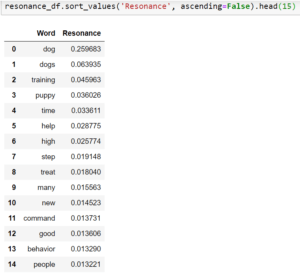
The idea of this research is to help understand how important certain words or topics could be to the keyword we are searching for.
For example, we can use the output shown above to be confident that if people are searching for information on training their dogs, we should be writing about commands, behavior, treats, and puppies (obviously), as those are some of the most salient terms identified.
Workflow 4 – Page Title N-gram Analysis
First things first; what’s an N-Gram? An N-Gram is a sequence of words and in our workflow, all we’re going to do is count the co-occurrence of N-Grams in the header tags of the pages we are analysing.
Remember one of the first processes in this script was to ‘save’ all our paragraph content in a ‘dictionary’? Well, at the same time we also saved all H1-H4 tags in another dictionary. You can see this in the third call of the script:

It’s this dictionary that we’re going to be analysing here.
The output is another dataframe showing a straightforward count of the co-occurrence of two- and three-word phrases in the header on ranking pages:
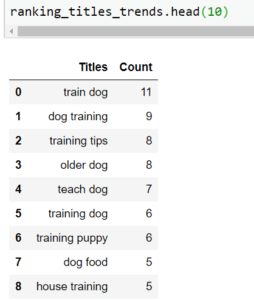
Again, we get some pretty interesting insights into what the best approach might be to optimise our page titles. For example, we see the word ‘tips’ being used a lot, as well as headers that speak to the age of the dog, house training, and dog food (presumably as an incentive).
This can help us plan and structure our landing pages.
Workflow 5 – Topic Modeling
Topic modeling , in this context, means using unsupervised machine learning to logically build out groups of topics that exist in the content we are analysing.
To expand on this a little more, imagine you are an editor for a magazine all about dogs and you’re running a special dog training edition. You’ve been given 100 articles written by freelancers, and your job is to read through the articles and categorise them. You have to do this by circling all the words you think are relevant to the categories you see – so you might circle all the words about ‘house training, ‘teaching commands’, ‘training puppies and older dogs’, ‘learning tricks’ etc. That is essentially the process that topic modelling goes through.
These ‘topics’ are going to be represented as a collection of words that can be seen in the dataframe thats looks like this:

Each row represents a ‘topic’, and each of the columns contains a word that is ‘salient’ or prominent within that topic.
The method of topic modeling is LDA , but there are many other models that can be used for topic modeling. However, hopefully this process demonstrates how it works and potential use cases.
The output dataframe does not ‘label’ the topical groupings; you have to look at them manually and assign the list of salient terms a label yourself.
However, it can be really useful for spotting trends and as a datapoint for content ideation (for example, you can create a content silo for each of the topics identified). It can also inform internal linking decisions (for example, focus on internal linking pages that would fit within one of your topical content groupings) and content categorisation.
For those using the script, you will notice that topics are currently labelled ‘Topic 0’, ‘Topic 1’, ‘Topic 2’ and so on. This is easy to change in the script, but as mentioned above, you will need to define those labels yourself based on the trends you see.
We’ll be revisiting these topical groupings in another workflow we’ll come onto shortly.
Workflow 6 – PoS Analysis on the SERPs
I won’t cover this in too much detail as it’s almost identical to what is covered in ‘Workflow 1’. The big difference is that we’re going to be running our PoS analysis on the actual content of the SERPs rather than the content of the pages ranking for that term.
If you want to find out why this is important, check out this talk I gave on the subject.
Workflow 7 – Question Extraction & Category Assignment
This is probably my favorite piece of analysis we can run through this script. What this part of the script will do is pull a list of questions in our copy (using a regex statement that looks for the start of a sentence that ends in a question mark).

It compiles the extracted list of questions in a dataframe that looks at some basic logic to eliminate anything that is obviously ‘noise’.

We then have an optional process, in which we revisit our topic modeling and create two functions.
The first will read the text of the question then match that to a topic and pull the ‘topic label’ into our dataframe (remember the label names you assigned in the topic modeling workflow). The second function will then pull through the words from that topical grouping.

Although there is often some ‘noise’, the process can pull through some really interesting insight on the questions being answered on top ranking landing pages and help you understand the type of content you might need to create to answer those questions yourself.
Our output dataframe looks like this (or click here to see a video version ):

Summarising all this information:
The most important thing to say is that this is not supposed to reveal some secret formula to on page optimisation or content strategy. What I hope is that it gives you some great insight into language trends and, most importantly, what your customers want when they are searching for relevant topics or keywords.
These insights can inform the decisions you make, and if making more informed decisions on the content you create improves the reach of your organic campaigns then more power to you! Thanks for reading – be curious, and good luck!






